
코학다식
[OS] CPU 스케줄링(CPU Scheduling) 본문
Basic Concepts
- 멀티프로그래밍은 CPU의 호율성을 극대화하기 위해 (프로세스) 스케줄링을 필요로 한다.
- 한 프로세스가 I/O 작업 등으로 CPU를 사용하지 않을 때, CPU가 아무 일도 하지 않는 일이 발생하지 않도록 다른 프로세스를 할당하는 등
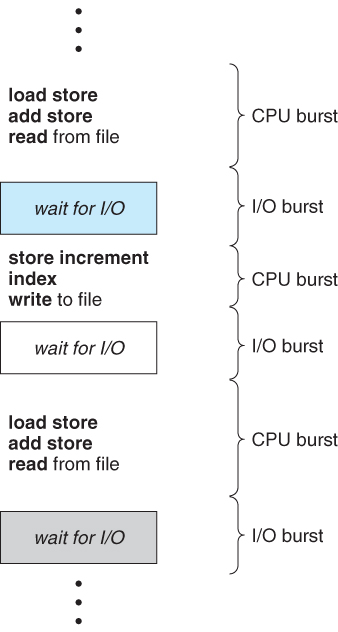
- CPU & I/O Burst Cycle
- 프로세스 실행은 CPU 실행과 I/O 대기의 사이클로 이루어진다.
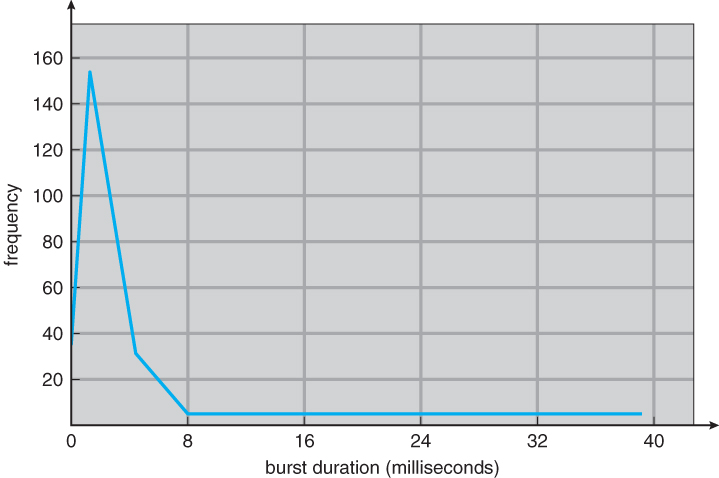
- CPU Burst distribution
- 보통 지수적인 특성을 가지며, 많은 짧은 CPU burst와 적고 긴 CPU burst를 가진다.
CPU Scheduler
- CPU Scheduler가 하는 일을 간단히 말하자면 ready queue에서 한 프로세스를 골라 실행하는 것이다.
- CPU 스케줄링은 크게 두 부분으로 나누어진다.
- algorithm: 어떤 프로세스를 선택할 것인가?
- Dispatcher: 현재 실행 중인 프로세스에서 넘어가 다른 프로세스를 실행하기 위해서는 현재 프로세스의 (PCB에) context를 저장해야 한다. 그 후 ready queue에 있던 새로운 프로세스의 PCB 내용을 불러온다. 실행은 이 프로세스의 program counter를 변화시키는 것을 의미한다.
- CPU 스케줄링 결정은 프로세스가 다음과 같은 상황에 처했을 때 일어난다.
- running state에서 waiting state로 이동
- running state에서 ready state로 이동
- waiting state에서 ready state로 이동
- terminates
- 첫 번째 경우와 네 번째 경우는 non-preemitive(비선점형)이다. 이 경우 프로세스는 스스로 이동한다.
- 나머지 경우는 preemitive(선점형)이다.
DIspatcher
- Dispatcher는 CPU 스케줄러(short-term 스케줄러)에 의해 선택된 프로세스의 컨트롤을 준다. 이는 다음을 포함한다.
- context switching
- switching to user mode
- jumping to the proper location in the user program to restart that program
- Dispatch latency: dispatcher가 한 프로세스를 멈추고 다른 프로세스를 시작하기까지 걸리는 시간
- 가능한 한 빨라야 한다.
- 일종의 오버헤드로서 줄이기 쉽지 않다.
- 그래서 dispachter보다는 CPU 스케줄링의 효율적인 알고리즘에 더 주목하고자 한다.
Scheduling Criteria
CPU 스케줄링의 효율성을 판단하는 기준들은 다음과 같다.
- 최대화
- CPU utilization: CPU를 가능한 한 바쁘게 유지한다. CPU를 얼마나 많이 사용하는가에 달렸다.
- Throughput: 얼마나 많은 자겁이 주어진 시간에 수행되었는지에 주목한다.
- 최소화
- Turnaround time: 특정 프로세스를 실행하는 데에 걸리는 시간을 의미한다. 프로세스가 생성 후 ready queue에 들어가 있던 시간과 실행이 완료되어 결과를 출력하기까지의 시간들의 합을 말한다.
- Waiting time: 프로세스가 ready queue에서 기다린 시간을 의미한다.
- Response time: 요청이 전달되고 첫 response가 생성될 때까지 걸린 시간을 의미한다. 첫 response와 output은 다르다.
Scheduling Algorithms
FCFS Scheduling
CPU에 먼저 요청하는 프로세스가 CPU에 먼저 할당된다.
비선점형이다.
작성, 이해가 쉽다.
구현이 FIFO queue로 쉽게 관리될 수 있다.
turnaroung time이 짧다.
평균 대기 시간이 길다.
Convoy effect가 발생한다.
여러 개의 프로세스가 하나의 긴 프로세스를 기다리게 될 수 있다.
긴 CPU burst를 가진 프로세스가 I/O queue로 이동한 후, 짧은 CPU burst를 가진 여러 프로세스가 빠르게 실행되고 I/O queue에 돌아오는 경우 CPU 효율이 낮아질 수 있다.
반대로 모든 I/O 프로세스가 CPU-bound 프로세스의 실행이 끝날 때까지 ready queue에서 기다릴 수 있다. 이 경우 device 효율이 낮아진다.
Shortest-Job-First(SJF) Scheduling
- 다음 CPU burst가 가장 짧은 프로세스를 먼저 실행한다.
- Non-preemitive:
- 일단 CPU에 프로세스가 할당되면 CPU burst가 끝날 때까지 선점될 수 없다.
- Preemitive:
- 만약 현재 실행 중인 프로세스의 남은 시간보다 더 짧은 CPU burst를 가진 프로세스가 도착하면, 선점한다.
- 이는 Shortest Remaining Time First(SRTF)로 알려져 있다.
- 주어진 프로세스의 집합에서 가장 작은 평균 대기 시간을 보인다.
- 다음 CPU 요청의 길이를 알기 어렵다. 이는 유저에게 요쳥하거나 예상할 수 있다.
Determining Next CPU Burst Length
- 길이만을 평가할 수 있다.
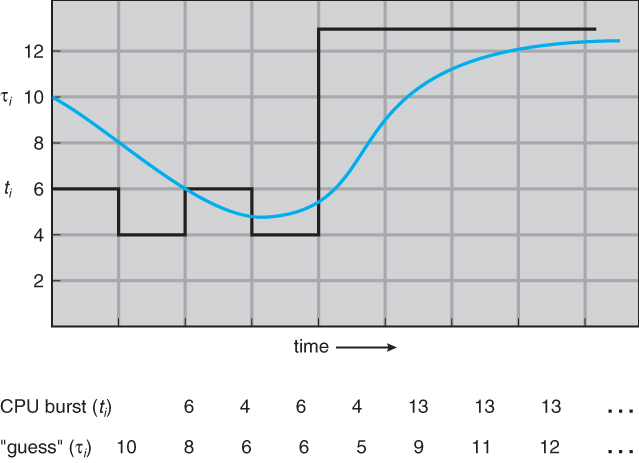
- exponential averaging과 이전 CPU burst의 길이를 사용해서 구할 수 있다.
- $estimate[ i + 1 ] = alpha * burst[ i ] + ( 1.0 - alpha ) * estimate[ i ]$
- alpha*와 *(1-alpha) 모두 1보다 작거나 같으므로, 다음 항은 앞선 항보다 더 적은 중요성을 가진다.
- 아래 이미지는 alpha가 1/2일 때 다음 CPU burst 길이를 예측한 것이다.
Priority Scheduling
- 우선순위 번호가 각각의 프로세스와 관련돼 있다.
- CPU는 높은 우선순위를 가진 프로세스에 할당된다.
- 이는 선점형과 비선점형으로 나뉜다.
- SJF는 우선순위가 예상된 다음 CPU burst 시간인 Priority Scheduling이다.
- 이는 starvation 문제를 일으킬 수 있다.
- 낮은 우선순위를 가진 프로세스가 절대 실행되지 않을 수 있다.
- 이 문제에 대한 해결책으로 aging이 있다.
- 시간이 지나면 프로세스의 우선순위를 증가하게 한다.
Round Robin(RR) Scheduling
- 각각의 프로세스는 CPU 시간의 작은 단위를 가진다.
- 이를 time quantum(= time slice)이라고 한다.
- 이 시간이 지나고 나면, 프로세스는 선점되고 ready queue의 끝에 추가된다.
- 만약 n개의 프로세스가 ready queue에 있고 time quantum이 q라면 각각의 프로세스는 q시간 동안 CPU를 점유하고 어떤 프로세스도 (n-1)q 시간 이상을 기다리지 않는다.
- 성능
- q가 커지면 FIFO와 유사해진다. turnaround가 좋다.
- q가 작으면 response time이 짧아지만 turnaround가 나빠진다. q는 최소한 context switching time보다는 길어야 한다.
- 만약 q가 굉장히 작은 경우, 이는 process sharing이라 불린다. 각각의 n개의 프로세스가 실제 프로세스의 1/n의 속도로 동작하는 프로세서를 가지는 것과 같은 효과를 준다.
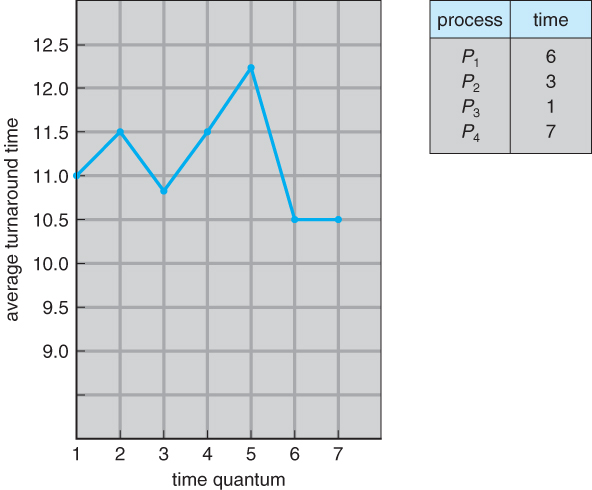
- time quantum이 증가하면 turnaround가 좋아지지만, 위의 표에서 알 수 있듯 모든 표에서 그런 것은 아니다.
- 보통 CPU burst의 80%보다 길어야 turnaround가 좋아진다.
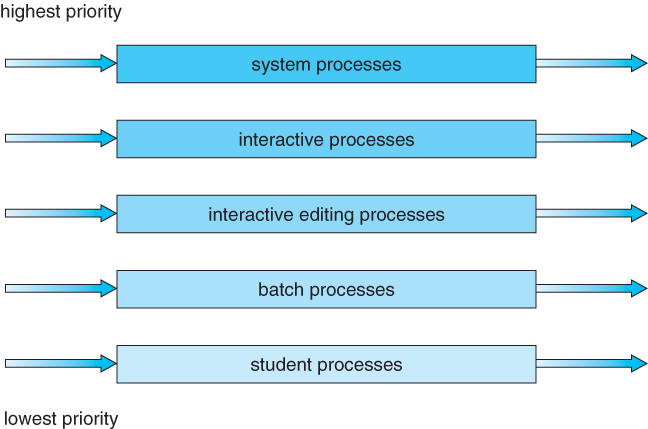
Multilevel Queue
- 이름 그대로 queue를 여러 개 사용한다.
- ready queue가 여러 개의 큐로 나뉜다.
- Foreground(interactive): response time이 짧아야 한다.
- Background(batch): 실행이 오래걸리나 interactive 환경일 필요가 없는 경우이다. 빨리 끝날수록 좋다. 즉, turnaround time이 짧은 게 좋다.
- 각각의 큐가 자신만의 스케줄링 알고리즘을 가진다.
- Foreground: RR
- Background: FCFS
- 큐 간에는 어떤 스케줄링 알고리즘이 적용될까? 큐 사이에서 이동하고 싶다면 어떻게 할까?
- 스케줄링은 큐 사이에서도 이루어져야 한다.
- Fixed priority scheduling: 가령, 모든 foreground에 있는 프로세스를 background에 있는 프로세스보다 먼저 수행한다. starvation의 가능성이 있다.
- Time slice: 각각의 큐가 그들의 프로세스 사이에서 스케줄할 수 있는 CPU 시간을 특정한 양으로 가진다.
- 스케줄링은 큐 사이에서도 이루어져야 한다.
Multilevel Feedback Queue
프로세느는 여러 큐 사이에서 이동할 수 있다.
- aging이 이 방식으로 구현될 수 있다.
Multilevel Feedback Queue는 다음 매개변수들에 의해 정의된다.
큐의 개수
각각의 큐의 스케줄링 알고리즘
언제 프로세스를 upgrade할지 결정하기 위해 사용되는 메서드
언제 프로세스를 demoteg할지 결정하기 위해 사용되는 메서드
프로세스가 서비스를 필요로 할 때 어느 큐에 그 프로세스가 들어가게 될지 결정하기 위해 사용되는 메서드
Example
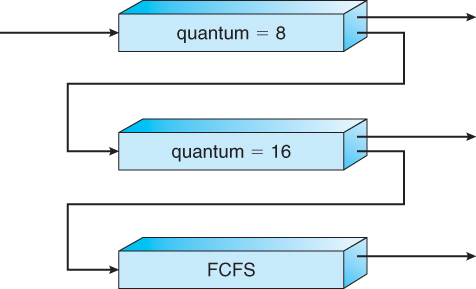
- 다음과 같이 큐가 구성되었고, 위에 위치할수록 우선순위가 높다고 가정해 보자. 가장 위의 큐는 RR 방식을 사용하며, time quantum이 8이다. 그 다음의 큐는 RR 방식을 사용하며 time quantum이 16이다.
- 가장 위의 큐에 새로운 작업이 들어오면, 그 작업은 8만큼의 CPU 시간을 할당받는다. 작업이 그 안에 끝나지 않으면, 그 다음 큐로 이동한다.
- 그 다음 큐(16)에서도 작업이 끝나지 않으면 마지막 큐로 이동한다.
- 마지막 큐의 작업은 FCFS 방식으로 이루어지는데, 이는 그 위의 큐들의 작업이 모두 끝나 그들이 비었을 때 가능하다.
Multiple-Processor Scheduling
- 여러 개의 CPU를 사용 가능할 때 CPU 스케줄링은 조금 더 복잡해진다.
- 모든 프로세스가 functionaliy에서 동일하다고 가정한다.
- 두 방식이 가능하다.
- Asymmetric multiprocessing: 하나의 프로세서만이 시스템 자료 구조에 접근할 수 있다. 데이터 공유가 편해진다.
- Sysmmetric multiprocessing(SMP): 각각의 프로세서가 공통 데이터 구조(ready queue)에 접근하고 그를 업데이트하며 자신만의 스케줄링을 하거나 ready process들의 사적인 큐를 가질 수 있다. SMP가 대부분의 multi-processor scheduling에 쓰인다.
- 각각의 CPU로 갈 작업을 분배하는 것과 관련된 이슈가 등장한다.
Load Balancing
- Load balancing은 SMP 시스템에서 모든 프로세서에 workload가 고루 분배되도록 한다.
- 각각의 프로세서에 ready queue가 존재하는 시스템(= 대부분의 현대적인 운영체제)에서만 필요하다.
- 두 개의 일반적인 접근법이 존재한다.
- Push migration: 특정 task가 주기적으로 각 프로세서들의 load를 확인하고 고루 분배한다. 일이 적은 곳에 일을 할당한다. 프로세스들의 load를 확인하는 별도의 프로세스가 존재한다.
- Pull migration: 일하지 않는 프로세서가 다른 바쁜 프로세서에서 대기 중인 일을 가져온다.
- 이 두 방식은 동시에 구현될 수 있다.
Processor Affinity
- 프로세스가 특정 프로세스에서 동작중일 때 캐시 메모리에 어떤 일이 일어날지 생각해 보자.
- 만약 시스템이 이동을 허용하면, 캐시 메모리에 있는 내용들도 해당 프로세서에서 사라지고 새 프로세서에서 다시 생겨나야 한다.
- 이는 많은 비용이 들어 대부분의 SMP 시스템은 프로세스의 이동을 피한다.
- Processor affinity는 프로세스를 같은 프로세서에서 동작하게 한다.
- 프로세스는 현재 동작하고 있는 프로세서에서 affinity를 가진다.
- 두 가지 경우가 존재한다.
- Soft affinity: 같은 프로세서에서 동작하려고 하지만 항상 그를 보장할 수는 없다. 이동할 수 있다.
- Hard affinity: 이동을 금지한다. 프로세서가 이동될 수 없음을 명시하는 시스템 콜을 제공한다.
Multicore Processors
최근의 경향은 하나의 물리적인 칩에 여러 코어를 둔다. 이를 multicore 프로세서라고 한다. 이는 CPU가 여러 개인 것과 같은 효과를 준다.
- 각각의 코어는 상태를 유지하기 위한 레지스터 집합을 가진다.
- multicore processor를 가진 시스템은 각각의 칩에 코어가 프로세서가 있는 시스템보다 빠르고 적은 전력을 소비한다.
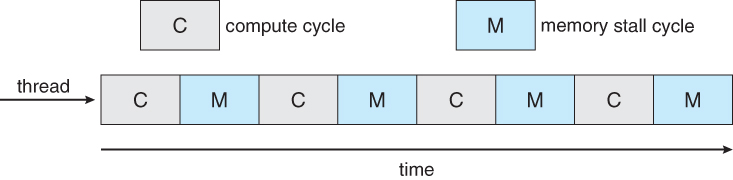
Memory stall 문제가 발생할 수 있다.
메모리에 접근할 때, 프로세서는 cache miss가 발생할 때마다 일정 시간 동안 데이터를 기다리는 데에 시간을 소비한다.
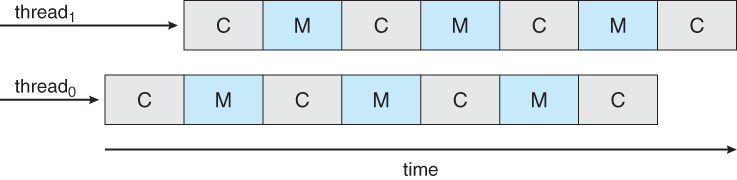
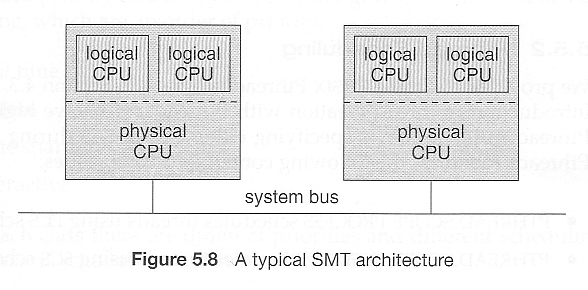
Simultaneous Multithreading (SMT)
memory stall 문제를 해결하기 위해, 하드웨어 디자이너들은 두 개 이상의 하드웨어 스레드가 각각의 코어에 할당된 multithreaded processor 코어를 구현했다. 이를 Simultaneous multithreading (SMT)라고 한다.
e.g. Intel's hyper-threadling technology
OS 관점에서, 각각의 하드웨어 스레드는 소프트웨어 스레드를 동작시키기 위해 사용 가능한 논리적 프로세서로 보인다.
실제로 동시에 동작하는 게 아니라, 동시에 동작하는 것처럼 보이는 것이므로 성능은 떨어진다.
'Fundamentals > OS' 카테고리의 다른 글
| [OS] 운영체제 동기화의 문제들(Bound-Buffered, Readers-Writers, Dining-Philosophers) (0) | 2020.09.01 |
|---|---|
| [OS] 병행성(concurrency)과 스레드(thread) (0) | 2020.09.01 |
| [OS] 협력하는 프로세스들 (0) | 2020.09.01 |
| [OS] 프로세스 생성과 종료 (0) | 2019.09.26 |
| [OS] 프로세스와 프로세스 스케줄링 (0) | 2019.09.24 |
